
Introduction #
Si le Web est un océan d’informations, Google en est le navigateur.
Mais comment un moteur de recherche parvient-il à distinguer l’essentiel du bruit, la crédibilité de la popularité ?
La réponse tient en un algorithme devenu mythique : PageRank.
Conçu à la fin des années 1990 par Larry Page et Sergey Brin à l’Université Stanford, PageRank a révolutionné la recherche sur Internet en introduisant une idée simple et élégante :
la valeur d’une page dépend de celles qui la citent.
C’est cette intuition, d’une sobriété mathématique remarquable, qui a transformé Google en empire informationnel.
1. L’intuition fondatrice : la réputation par les liens #
Avant PageRank, les moteurs de recherche se contentaient d’analyser les mots-clés. Une page contenant souvent le mot « voiture » était jugée plus pertinente pour ce terme.
Mais cette approche textuelle favorisait le bourrage de mots et ignorait la crédibilité des sources.
PageRank a introduit un principe de démocratie hypertextuelle :
chaque lien vers une page est considéré comme un vote de confiance, une marque de reconnaissance.
Et plus un site reconnu vote pour vous, plus votre autorité augmente.
Autrement dit :
- Un lien d’un site obscur a peu de poids.
- Un lien depuis une page influente (par exemple Wikipédia) vaut beaucoup plus.
2. Le modèle mathématique #
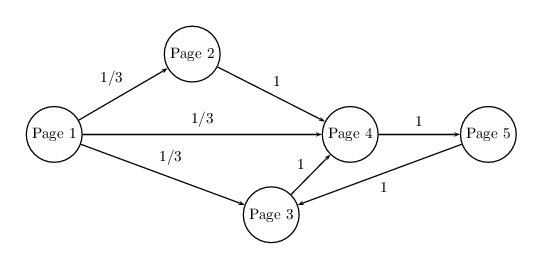
Pour formaliser cette idée, Larry Page et Sergey Brin ont modélisé le Web comme un graphe orienté :
- chaque page web est un nœud ;
- chaque lien hypertexte est une flèche d’un nœud vers un autre.
La formule fondamentale du PageRank est :
PR(A) = (1 - d) + d * Σ [ PR(T_i) / C(T_i) ]
où :
- ( PR(A) ) : score de PageRank de la page A
- ( T_i ) : pages contenant un lien vers A
- ( C(T_i) ) : nombre de liens sortants de la page ( T_i )
- ( d ) : facteur d’amortissement (souvent ≈ 0,85)
Interprétation #
Imagine un internaute fictif, le surfeur aléatoire, qui parcourt le Web en cliquant sur des liens :
- avec probabilité ( d ), il suit un lien depuis la page actuelle ;
- avec probabilité ( 1 - d ), il saute vers une page au hasard.
Le PageRank correspond à la probabilité à long terme que ce surfeur se trouve sur une page donnée.
Mathématiquement, il s’agit du vecteur propre principal d’une matrice de transition stochastique — autrement dit, une chaîne de Markov appliquée au graphe du Web.
3. Calcul du PageRank #
Le calcul se fait de manière itérative :
- Initialiser toutes les pages avec le même score (souvent 1/N).
- Appliquer la formule pour recalculer le score de chaque page.
- Répéter jusqu’à ce que les valeurs convergent (différence entre deux itérations < seuil).
Cette méthode est connue sous le nom de méthode de la puissance (power iteration), utilisée pour trouver le vecteur propre dominant d’une matrice.
Exemple conceptuel #
Si la page A pointe vers B et C, et que B et C pointent vers A, le système converge vers un équilibre où chaque page reçoit un score proportionnel à sa popularité structurelle.
4. L’élégance et la puissance du modèle #
Ce qui a rendu PageRank si révolutionnaire, c’est qu’il reposait sur :
- la topologie du Web, et non sur le texte ;
- une formule récursive simple mais expressive ;
- une base probabiliste solide, garantissant stabilité et convergence.
Ce système récompensait naturellement les pages de qualité (souvent citées) plutôt que celles truffées de mots-clés.
C’est ainsi que Google, dès ses débuts, a surpassé ses concurrents (Altavista, Yahoo, Lycos) en pertinence.
5. Les limites du PageRank #
Aussi élégant soit-il, PageRank n’est pas parfait.
Son modèle a montré plusieurs failles avec le temps :
a. Manipulation et spam #
Des fermes de liens (link farms) sont apparues pour gonfler artificiellement le score d’un site.
L’idée : créer des centaines de pages qui se citent entre elles pour simuler de la popularité.
b. Absence de sémantique #
PageRank ne comprend pas le sens du contenu.
Un lien peut être critique ou ironique — l’algorithme le considère toujours comme un vote positif.
c. Injustice pour les nouveaux sites #
Une page sans liens entrants commence avec un score faible, même si son contenu est excellent.
Il faut du temps (et des citations) pour émerger.
d. Inadaptation au Web moderne #
À l’époque de sa conception, le Web était plus statique.
Aujourd’hui, les pages sont dynamiques, éphémères, personnalisées — un terrain où la structure des liens n’est plus aussi stable.
6. L’évolution dans les algorithmes de Google #
Google n’a jamais abandonné l’idée du PageRank, mais il l’a intégré dans un écosystème algorithmique bien plus vaste.
Le classement actuel des pages repose sur des centaines de signaux :
- Contenu sémantique (traité par des modèles de langage comme BERT).
- Qualité du site (critères E-E-A-T : Experience, Expertise, Authoritativeness, Trustworthiness).
- Comportement utilisateur (clics, rebonds, durée de visite).
- Performance technique (vitesse, mobile, HTTPS…).
Le PageRank moderne reste présent sous une forme pondérée, combiné à des métriques de confiance et pertinence contextuelle.
7. Héritage et portée conceptuelle #
PageRank n’est pas seulement un algorithme ; c’est une philosophie de la connaissance :
celle selon laquelle la valeur d’une information émerge de l’écosystème de références qui l’entoure.
Son principe d’autorité par les liens a inspiré :
- les systèmes de recommandation,
- les algorithmes de citation académique (comme Eigenfactor),
- et même des approches de classement social ou de centralité dans les graphes (network science).
Conclusion #
Le PageRank demeure une leçon de sobriété algorithmique :
une équation, une intuition, et un monde bouleversé.
Sa force n’a jamais résidé dans la complexité, mais dans sa capacité à formaliser une idée humaine :
la crédibilité se construit par reconnaissance mutuelle.
Dans l’ère du machine learning et des grands modèles de langage, PageRank nous rappelle que la pertinence peut encore naître d’un raisonnement mathématique simple — pour peu qu’il s’appuie sur une intuition juste de la manière dont les humains donnent du sens à l’information.